
There are important decisions to be made across the entire journey to implementing a cloud native security strategy, from initial visibility to automation of prevention and response.
This blog post will guide you through the implementation decisions across that journey, from initial, frictionless API based visibility to agents with deeper visibility and protection. Every team starts somewhere different, and the key is to steer your own journey based on a conscious decision around risk tolerance.
Getting started on the journey quickly and easily
A common question from teams just getting started with cloud native security is, “does your solution require an agent?” Most practitioners start with agentless implementations of some kind because of the ease of deployment and speed.
For example, in a typical start to a cloud native security journey, practitioners will employ shift-left security testing and preventive controls. Infrastructure as Code scanning is an example of what would happen at this stage, and that can be done through a simple agentless Helm chart installation and binary download.
Below are a few other examples of quick, easy ways to start with an agentless implementation:
| Agentless Approach | Purpose |
| Kubernetes admission controller | The native system using and enforcing the response from a remote Policy Decision Point |
| Downloading Kubernetes manifests (YAML files) |
Useful for scanning images in a registry or repo in a Kubernetes environment |
| Download a binary or install as a Helm chart | IaC template scanning |
| Connect to the serverless app via API | Function scanning via the cloud account or CI/CD pipeline |
| Cloud service account APIs | Cloud service account misconfiguration scanning |
| Cloud workload scanning via cloud service APIs | Gain a quick view of risks in running cloud workloads |
Understanding the tradeoffs between security and ease of implementation
But the journey is not ‘one-size-fits-all.’ Every team has a different set of applications with different sensitivity and security implications. For example, business-critical applications that handle sensitive data governed by compliance regulations like HIPAA or PCI-DSS have more stringent security requirements. In general, as the strength of security controls increases, so does the overall involvement of the implementation method.
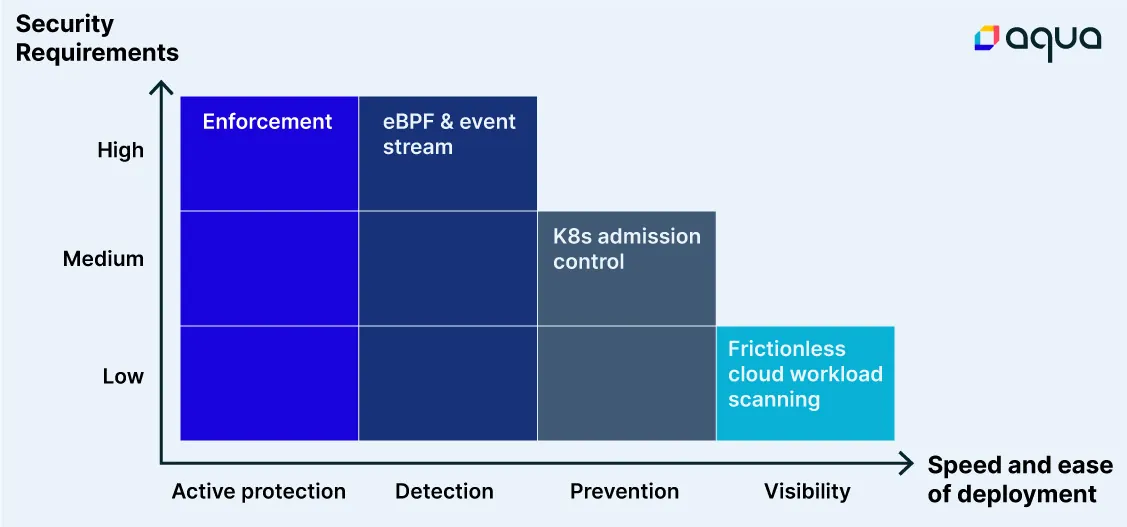
And of course there is a wide range of variation across visibility and active response. For example, not all types of visibility are the same. Deeper levels – such as kernel-level visibility using eBPF – require a greater level of effort to implement. And some response methods are less intrusive, like a Kubernetes admission controller that acts before a workload is run.
Ignoring the tradeoff between security capabilities and ease of deployment has consequences
Where practitioners get in trouble is when they make their decisions around security controls based on implementation method versus security requirements. Most typically, practitioners make the mistake of using only light, agentless visibility for applications that handle sensitive data because they can get up and running quickly. Less common, but still a similar issue, is when practitioners use implementation methods that are not justified by the security risk of the application. Some applications simply don’t perform critical functions, so there is no need for a team to spend time and effort on heavier implementation. These teams run the risk of wasting precious resources. Business critical applications could also have both in-depth, active controls as well as passive, agentless visibility.
In any case, it is helpful to have a view of both from the same platform for consistency and noise reduction.
Agent vs agentless in cloud native
In cloud native, agent-based protection can provide the active protection required for business critical applications. But it is important to consider that, in the context of cloud native, the term “agent” is a bit of a misnomer.
Historically, “agents” have been used with Host Intrusion Protection Systems (HIPS), Endpoint Protection Platforms (EPP), Endpoint Detection and Response (EDR) solutions, and more. In these traditional solutions, agents are installed on the endpoint and alter the configuration of the operating systems. In cloud native none of the active control options – or agents – alter the configuration of the operating system:
| Instrumentation methods in cloud native | Purpose |
| Sidecar container | For securing an environment like Fargate, where host access is limited |
| Code snippets deployed as a Lambda layer | For securing running functions |
| Containers | For deep runtime capabilities (like blocking executables) for containerized environments |
| eBPF program | Deep kernel-level visibility into Linux runtime events |
| Kernel module | Extends kernel functionality at runtime |
Tradeoffs between agent and agentless protection
Ideally, teams can make an informed decision about what kind of implementation they would prefer based on risk rolerance and full visibility into the trade-offs. Below is a summary of the tradeoffs between cloud native agent-based and agentless implementations to help you determine the most adequate implementation for your own level of risk tolerance in any application:
| Agent-based CWPP Implementation | Agentless CWPP Implementation |
| Real-time enforcement in runtime. This includes automating preventive or corrective controls based on contextual datapoints. | Visibility with no option for response. For example: it is possible to detect an exceeded CPU limit, but not possible to stop a workload from running or to prevent a malicious payload from executing in production based on this information. |
| Deep, real-time visibility at the kernel level (with eBPF) or compute side. | Limited visibility with lower data resolution. There is no visibility into the compute side (e.g., memory and CPU usage), no application context in Kubernetes, and no visibility into Container-as-a-Service (CaaS) deployments. |
| Deployment flexibility across hybrid environments. Agents can be deployed in public and private cloud environments and for on-premises workloads. | Reliance on public cloud environments. There is no way to get visibility into on-prem workloads, making visibility across hybrid environments impossible. |
How Aqua can help
Aqua recently announced new, frictionless Cloud Workload Scanning and Cloud Security Insights to give organizations a quick view of their top cloud security risks. These capabilities combined in the Aqua Platform mean that time-strapped security teams can get visibility into top cloud workload risk within minutes as well as the ability to do something about it. For any tech stack that includes even one business critical application, the Aqua Platform gives teams the option to optimize their efforts across frictionless visibility, active prevention in shift-left as well as response in runtime. The Aqua Platform is a CNAPP, as the term has been coined by Gartner, helping time-strapped Security, IT and DevOps teams reduce noise across multiple vendors and achieve defense in depth across the full application lifecycle.
Conclusion
Agentless solutions provide quick visibility, shift-left capabilities, and some visibility for cloud workloads. This may be adequate for non-business-critical applications, in which you don’t want to expend the effort and resources to deploy agents. Agent-based cloud native security solutions provide deeper, real-time visibility and rapid runtime response. This is perfect for business-critical applications that need deep levels of visibility and strong prevention and response capabilities.
In a recent practitioner interview, a VP of Cloud Architecture, Cybersecurity & Risk Management at a Fortune 500 risk assessment firm put it succinctly:
“You will always need both agents and agentless, they both have their areas where they can work really well.”
Sounds like a win-win.
Learn more about Aqua’s recent Cloud Workload Scanning capabilities.
