
The National Vulnerability Database (NVD), while a valuable source of vulnerability information, is inadequate for today’s cloud native ecosystem and the teams tasked with protecting it. The complex array of platforms, technologies, and deployment methodologies at play in cloud native environments means that detecting and remediating vulnerabilities (e.g., CVEs) does not eliminate all potential attack vectors. With this in mind, we crafted Aqua CyberCenter with the goal of establishing a comprehensive and reliable source of security risk information, cataloguing not only public CVEs but also vendor security advisories, malware, and our primary threat research.
In this blog, I’ll explore how Aqua extends beyond the NVD to enhance cybersecurity intel for cloud native DevOps, from detection to identification to remediation – a process made possible by Aqua CyberCenter. First, let’s review the limitations of the NVD’s vulnerability information and establish an understanding on how Aqua CyberCenter evolves the standard for detailed, actionable security risk insight.
Level-setting on the Basics: Vulnerabilities 101
Vulnerabilities and Weaknesses:
In the simplest terms, a vulnerability is a segment of software code that could, potentially, be exploited. This definition holds true regardless of the intentions of the person doing the exploiting and doesn’t even consider the existence of an exploit at all. If there’s a part of the code that can be used to perform unauthorized actions within a system (e.g., SQL Injection, DDoS attacks, XSS injection), then it is considered a vulnerability.
To clarify further, a weakness is a categorical mistake in code that can lead to specific exploitable instances, which we catalogue as vulnerabilities enumerated with unique identifiers to help detection and remediation.
Common Vulnerabilities and Exposures (CVE):
A CVE is nothing more than one example of a unique identifier of vulnerabilities. The CVE moniker was established by the U.S. Department of Homeland Security organization MITRE as a way to engender security best practices in software as evidence of its potential threat to the public grew. These CVEs are catalogued in the National Vulnerability Database (NVD).
National Vulnerability Database (NVD):
The NVD is the de facto U.S. government-backed repository of CVE data, managed by the National Institute of Standards and Technology (NIST). The NVD includes a wide variety of information, including security checklists, security-related software flaws, misconfigurations, product names, and – most notoriously – standardized risk severity metrics.
Common Platform Enumeration (CPE):
Common Platform Enumeration is a standardized method of defining applications, operating systems, and hardware present among an enterprise’s software and cloud ecosystem. These attributes document various aspects of vendor, version, edition, language, and hardware specifics related to the software. This information can have a direct impact on the accuracy and actionability of results generated by vulnerability scanners. We will explore this topic more in a future blog related to our vulnerability scanner’s Red Hat certification.
Limitations of the NVD
First, because the NVD is a government-backed resource that relies on a finite number of dedicated security researchers and analysts to maintain it, the explosive growth in the number of open source components has increased the backlog of vulnerabilities that need to be processed. This leads to a delay in the publication of useful information in the vulnerability record, often measured in weeks or months. Trusting only the NVD for vulnerability details or remediation information means leaving yourself potentially exposed to attack during this information drought.
Secondly, while there are a growing number of CVE numbering authorities (CNAs) helping to fill the CVE funnel, NIST’s team of analysts assigned to embellish the CVE records with additional security information are limited in time and resources. This often leads to bare-bones descriptions and analysis for a large portion of vulnerabilities. Making informed prioritization and remediation decisions on stingy details may not fit into your security team’s idea of best practices.
The third caveat: not all vulnerabilities that are discovered get the iconic CVE moniker. Vendor security advisories or proprietary security research are not obliged to be assigned a CVE nor to be tracked in the NVD. In these scenarios, leveraging only the NVD can leave a significant number of vulnerabilities unidentified within your codebase.
In short, the NVD is an essential resource, but it should not be your only resource for identifying detected vulnerabilities within your cloud native software ecosystem. Of course, this brings us to the topic of detection…
Visualizing the Full Story, from Detection to Identification to Remediation
When discussing “finding” vulnerabilities within a particular package, we are inherently discussing two distinct topics: “detecting” vulnerabilities and “identifying” vulnerabilities.
The identification part of the story involves the NVD and other security resources that provide technical details that match specific criteria that help us identify or classify a particular vulnerability. The detection part of the story depends on the security solution you are using, and the analysis method used to sift through code and artifacts to reveal a vulnerability within the application structure, code, containers, or otherwise.
With this in mind, tools along the spectrum of security solutions are inherently limited by their ability to accurately and reliably detect and, subsequently, identify vulnerabilities. Moreover, any remediation activity (e.g., triage, patching, compensating controls, etc.) will be directly informed by such detection and identification. At this point, it should be clear that – regardless of whichever security tools you’re implementing – the use of the NVD as a sole information source for identification and response prioritization puts unnecessary restraints on any security program, but especially in the cloud native realm where many open source packages are used regularly and updated frequently.
How Aqua Enhances Cloud Native Security Intelligence
Aqua’s CyberCenter is a proprietary database composed of data sourced and curated by Aqua’s dedicated cybersecurity research teams. It provides detailed, actionable information to help prioritize and remediate cloud native security risks. This approach enables Aqua to provide greater insight and breadth of coverage than the NVD for supported languages, frameworks, and artifacts.
Curated Intel to Form a Single Source of Truth
Aqua CyberCenter compiles multiple data sources into an informed, single verdict of vulnerability. This extensive assortment of vulnerabilities and risks ensures organizations don’t fail to identify potential risks due to the absence of an associated CVE, a delay in the CVE’s publication, or a lack of actionable insight in the security record. The diagram below is a conceptual illustration of the Aqua CyberCenter’s data sources and the cybersecurity research team’s process of analysis and curation.
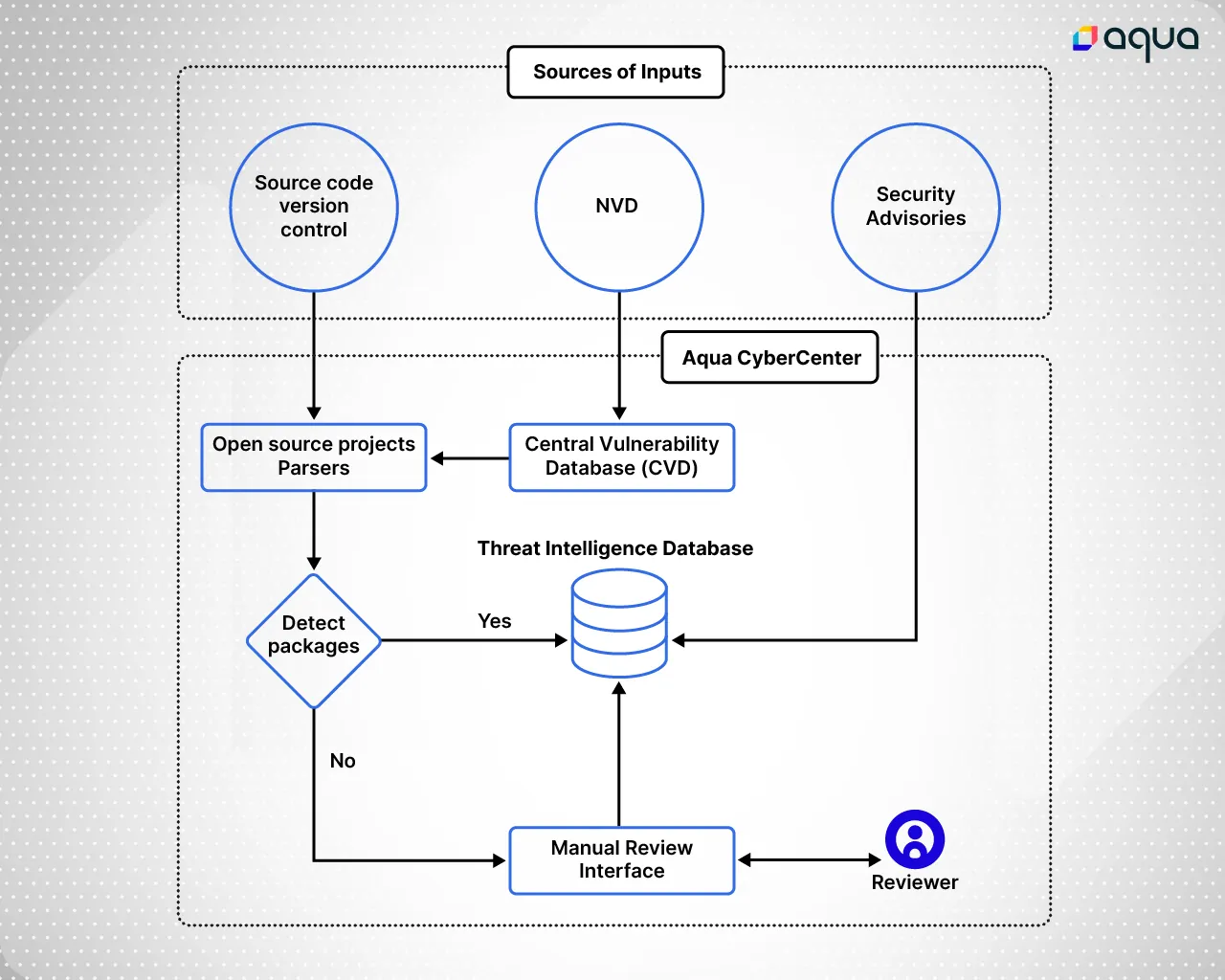
Research-Driven Open Source Security Risk Insight
With the growth in popularity and number of open source components in the wild, the diversity of code quality and security standards grows with it. Some developers and community groups uphold high security standards, others do not, and many have not yet adopted the practice of disclosing vulnerabilities to the NVD or relevant CNAs. To ensure this data is not lost to security and development teams, Aqua’s CyberCenter includes research into open source projects’ self-issued security advisories and issue histories to identify vulnerabilities.
To illustrate such potential discrepancies, I’ll provide an example.
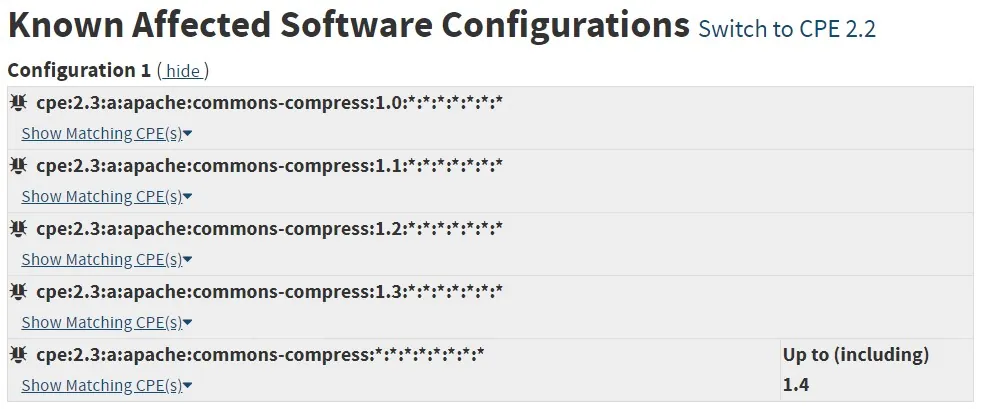
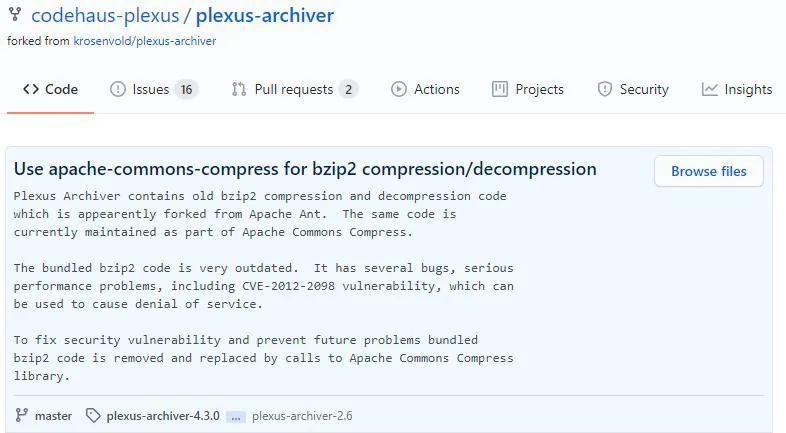
In the images above, we see that, as per the NVD, CVE-2012-2098 is applicable only to the Apache Common Compress artifacts, but Aqua’s detection algorithm was able to detect another artifact (e.g., Plexus-Archiver) as vulnerable as well, despite this information being excluded from the NVD.
Accurate Vulnerability Classification
Frequently, there may be discrepancies between the NVD’s vulnerability classifications and vendors’ classifications. This means that, while the NVD may not document any known patch to address a given vulnerability, the software vendor may have “backported” fixes available and reclassified the vulnerability. In such instances, the NVD may report a High severity rating while the vendor notes a Negligible severity rating. By aggregating this information, the Aqua CyberCenter provides a more accurate representation of security risk to assist prioritization and triage.
Diverse Security Risk Information
Aqua CyberCenter includes detailed descriptions, security risk information, risk classifications, exploit details, and remediation guidance for the security risks it catalogues. In stark contrast to the NVD, Aqua CyberCenter does this for publicly available vulnerabilities (CVEs), vendor-issued security advisories, malware, and proprietary Aqua research and threat intelligence.
Accurate Risk Detection and Identification
Aqua’s unique package detection methodology helps to improve scan results and realize the full value of Aqua CyberCenter. Aqua accurately detects and identifies package names and specific versions while minimizing false positives and false negatives when associated with vulnerabilities for the identified packages. The following table provides a few examples of the files our cybersecurity research team examines to ensure accuracy:
| Language | Files Examined |
| Java | JAR files (pom.properties or MANIFEST.MF within the jars). Note: jars can be extracted from other JAR, WAR, or EAR files. |
| Python | METADATA or pkg-info files |
| Php | composer.lock files |
| Ruby | gemspec files |
| NPM | package.json files |
| Nuget | .csproj or .config or project.json or .deps.json files |
Ultimately, Aqua’s approach to vulnerability detection, identification, evaluation, and remediation helps to evolve security standards beyond the NVD as a single source of risk information for a modern cloud native application ecosystem.
