Kubernetes Architecture
Learn about Kubernetes Architecture, components, and design principles and see a sample installation and setup procedure.
In this page, you’ll learn everything you need to know about Kubernetes Architecture:
- Kubernetes Architecture
- What is Kubernetes?
- Kubernetes Components and Architecture
- Kubernetes Concepts
- Kubernetes Design Principles
- Sample Installation and Setup of Kubernetes
- Summary
What is Kubernetes?
Kubernetes is an open source orchestration tool developed by Google for managing microservices or containerized applications across a distributed cluster of nodes. Kubernetes provides highly resilient infrastructure with zero downtime deployment capabilities, automatic rollback, scaling, and self-healing of containers (which consists of auto-placement, auto-restart, auto-replication , and scaling of containers on the basis of CPU usage).
The main objective of Kubernetes is to hide the complexity of managing a fleet of containers by providing REST APIs for the required functionalities. Kubernetes is portable in nature, meaning it can run on various public or private cloud platforms such as AWS, Azure, OpenStack, or Apache Mesos. It can also run on bare metal machines.
For further reading, see Kubernetes Documentation: Why Containers ›
Kubernetes Components and Architecture
Kubernetes follows a client-server architecture. It’s possible to have a multi-master setup (for high availability), but by default there is a single master server which acts as a controlling node and point of contact. The master server consists of various components including a kube-apiserver, an etcd storage, a kube-controller-manager, a cloud-controller-manager, a kube-scheduler, and a DNS server for Kubernetes services. Node components include kubelet and kube-proxy on top of Docker.
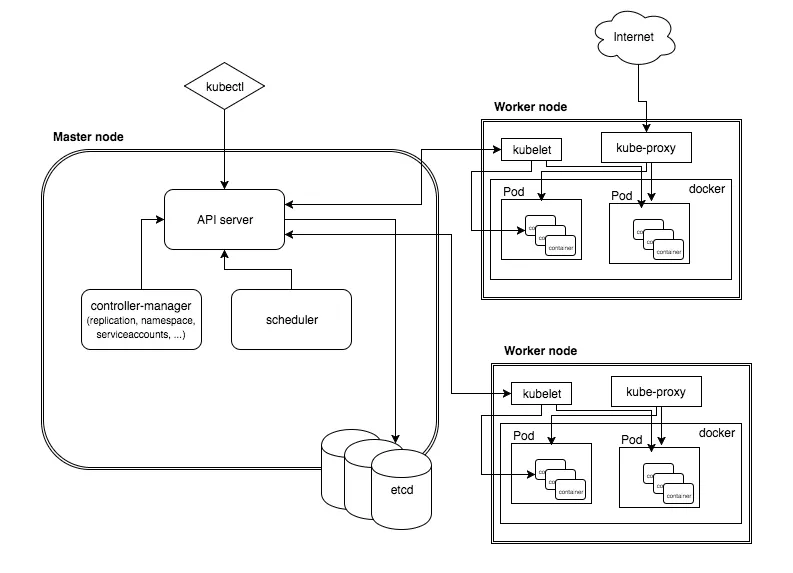
Master Components
Below are the main components found on the master node:
- etcd cluster – a simple, distributed key value storage which is used to store the Kubernetes cluster data (such as number of pods, their state, namespace, etc), API objects and service discovery details. It is only accessible from the API server for security reasons. etcd enables notifications to the cluster about configuration changes with the help of watchers. Notifications are API requests on each etcd cluster node to trigger the update of information in the node’s storage.
- kube-apiserver – Kubernetes API server is the central management entity that receives all REST requests for modifications (to pods, services, replication sets/controllers and others), serving as frontend to the cluster. Also, this is the only component that communicates with the etcd cluster, making sure data is stored in etcd and is in agreement with the service details of the deployed pods.
- kube-controller-manager – runs a number of distinct controller processes in the background (for example, replication controller controls number of replicas in a pod, endpoints controller populates endpoint objects like services and pods, and others) to regulate the shared state of the cluster and perform routine tasks. When a change in a service configuration occurs (for example, replacing the image from which the pods are running, or changing parameters in the configuration yaml file), the controller spots the change and starts working towards the new desired state.
- cloud-controller-manager – is responsible for managing controller processes with dependencies on the underlying cloud provider (if applicable). For example, when a controller needs to check if a node was terminated or set up routes, load balancers or volumes in the cloud infrastructure, all that is handled by the cloud-controller-manager.
- kube-scheduler – helps schedule the pods (a co-located group of containers inside which our application processes are running) on the various nodes based on resource utilization. It reads the service’s operational requirements and schedules it on the best fit node. For example, if the application needs 1GB of memory and 2 CPU cores, then the pods for that application will be scheduled on a node with at least those resources. The scheduler runs each time there is a need to schedule pods. The scheduler must know the total resources available as well as resources allocated to existing workloads on each node.
Node (worker) components
Below are the main components found on a (worker) node:
- kubelet – the main service on a node, regularly taking in new or modified pod specifications (primarily through the kube-apiserver) and ensuring that pods and their containers are healthy and running in the desired state. This component also reports to the master on the health of the host where it is running.
- kube-proxy – a proxy service that runs on each worker node to deal with individual host subnetting and expose services to the external world. It performs request forwarding to the correct pods/containers across the various isolated networks in a cluster.
Kubectl
kubectl command is a line tool that interacts with kube-apiserver and send commands to the master node. Each command is converted into an API call.
For further reading, see Kubernetes Documentation: Kubernetes Components ›
Kubernetes Concepts
Making use of Kubernetes requires understanding the different abstractions it uses to represent the state of the system, such as services, pods, volumes, namespaces, and deployments.
- Pod – generally refers to one or more containers that should be controlled as a single application. A pod encapsulates application containers, storage resources, a unique network ID and other configuration on how to run the containers.
- Service – pods are volatile, that is Kubernetes does not guarantee a given physical pod will be kept alive (for instance, the replication controller might kill and start a new set of pods). Instead, a service represents a logical set of pods and acts as a gateway, allowing (client) pods to send requests to the service without needing to keep track of which physical pods actually make up the service.
- Volume – similar to a container volume in Docker, but a Kubernetes volume applies to a whole pod and is mounted on all containers in the pod. Kubernetes guarantees data is preserved across container restarts. The volume will be removed only when the pod gets destroyed. Also, a pod can have multiple volumes (possibly of different types) associated.
- Namespace – a virtual cluster (a single physical cluster can run multiple virtual ones) intended for environments with many users spread across multiple teams or projects, for isolation of concerns. Resources inside a namespace must be unique and cannot access resources in a different namespace. Also, a namespace can be allocated a resource quota to avoid consuming more than its share of the physical cluster’s overall resources.
- Deployment – describes the desired state of a pod or a replica set, in a yaml file. The deployment controller then gradually updates the environment (for example, creating or deleting replicas) until the current state matches the desired state specified in the deployment file. For example, if the yaml file defines 2 replicas for a pod but only one is currently running, an extra one will get created. Note that replicas managed via a deployment should not be manipulated directly, only via new deployments.
For further reading, see Kubernetes Documentation: Kubernetes Concepts ›
Kubernetes Design Principles
Kubernetes was designed to support the features required by highly available distributed systems, such as (auto-)scaling, high availability, security and portability.
- Scalability – Kubernetes provides horizontal scaling of pods on the basis of CPU utilization. The threshold for CPU usage is configurable and Kubernetes will automatically start new pods if the threshold is reached. For example, if the threshold is 70% for CPU but the application is actually growing up to 220%, then eventually 3 more pods will be deployed so that the average CPU utilization is back under 70%. When there are multiple pods for a particular application, Kubernetes provides the load balancing capacity across them. Kubernetes also supports horizontal scaling of stateful pods, including NoSQL and RDBMS databases through Stateful sets. A Stateful set is a similar concept to a Deployment, but ensures storage is persistent and stable, even when a pod is removed.
- High Availability – Kubernetes addresses highly availability both at application and infrastructure level. Replica sets ensure that the desired (minimum) number of replicas of a stateless pod for a given application are running. Stateful sets perform the same role for stateful pods. At the infrastructure level, Kubernetes supports various distributed storage backends like AWS EBS, Azure Disk, Google Persistent Disk, NFS, and more. Adding a reliable, available storage layer to Kubernetes ensures high availability of stateful workloads. Also, each of the master components can be configured for multi-node replication (multi-master) to ensure higher availability.
- Security – Kubernetes addresses security at multiple levels: cluster, application and network. The API endpoints are secured through transport layer security (TLS). Only authenticated users (either service accounts or regular users) can execute operations on the cluster (via API requests). At the application level, Kubernetes secrets can store sensitive information (such as passwords or tokens) per cluster (a virtual cluster if using namespaces, physical otherwise). Note that secrets are accessible from any pod in the same cluster. Network policies for access to pods can be defined in a deployment. A network policy specifies how pods are allowed to communicate with each other and with other network endpoints.
- Portability – Kubernetes portability manifests in terms of operating system choices (a cluster can run on any mainstream Linux distribution), processor architectures (either virtual machines or bare metal), cloud providers (AWS, Azure or Google Cloud Platform), and new container runtimes, besides Docker, can also be added. Through the concept of federation, it can also support workloads across hybrid (private and public cloud) or multi-cloud environments. This also supports availability zone fault tolerance within a single cloud provider.
For further reading, see Kubernetes Documentation: Kubernetes: An Overview ›
Sample Installation and Setup of Kubernetes
Note: In this example, from X-Team’s Introduction to Kubernetes Architecture , all the components are installed inside a single docker container, acting as both master and worker node. This is solely for demonstration purposes.
Installing Kubernetes
- Set the K8S_VERSION env variable to the latest stable Kubernetes release, for later retrieval:
export K8S_VERSION=$(curl -sS https://storage.googleapis.com/kubernetes-release/release/stable.txt)- Assuming the host’s architecture is amd64, set the ARCH env variable:
export ARCH=amd64- Run the
hypercubeDocker container, which itself takes care of installing all the Kubernetes components. It requires special privileges, which are explained below.
docker run -d --volume=/:/rootfs:ro \
--volume=/sys:/sys:rw --volume=/var/lib/docker/:/var/lib/docker:rw \
--volume=/var/lib/kubelet/:/var/lib/kubelet:rw --volume=/var/run:/var/run:rw \
--net=host --pid=host --name=hyperkube-installer \
--privileged gcr.io/google_containers/hyperkube-${ARCH}:${K8S_VERSION}\
/hyperkube kubelet --containerized \
--hostname-override=127.0.0.1 --api-servers=http://localhost:8080 \
--config=/etc/kubernetes/manifests --allow-privileged --v=2- Run the command
docker psto see all the running containers started by hypercube, for example a container created with the command"/hyperkube apiserver".
The volume parameters are required to mount and give access to the host’s /root , /sys , /var/run and /var/lib/docker filesystems inside the container instance. The --privileged option grants access to all devices of the host, namely to start new containers. Parameters --net=host and --pid=host allow access to the network and PID namespace of the host.
hypercube's Docker image is available from Google’s Container Registry (GCR), we use ARCH and K8S_VERSION env variables to construct the full path to the image that fits our environment:
gcr.io/google_containers/hyperkube-${ARCH}:${K8S_VERSION}Deploying Pods
- Start a bash shell inside the hypercube container:
docker exec -it hyperkube-installer /bin/bash- Export the Kubernetes version and processor architecture inside the container:
export K8S_VERSION=$(curl -sS https://storage.googleapis.com/kubernetes-release/release/stable.txt)
export ARCH=amd64- Download the kubectl command line tool into
/usr/bin/kubectland make it executable:
curl -sSL "http://storage.googleapis.com/kubernetes-release/release/$K8S_VERSION/bin/linux/$ARCH/kubectl" > /usr/bin/kubectl
chmod +x /usr/bin/kubectl- Now you can run
kubectlcommands to retrieve information on Kubernetes state:
kubectl get nodes
kubectl get pods
kubectl get namespaces- Start deployment of a sample nginx pod and exit the container:
kubectl run nginx --image=nginx --port=80 ; exit- Run the command
dockerpsto see the new nginx containers running on the host. - Declare the nginx pod deployment as a service and map port 80 of the nginx service to port 8080 on the host:
docker exec -it hyperkube-installer /bin/bash
kubectl expose deployment nginx --port=8080 --target-port=80- Check that the nginx service is ready and was assigned an IP, and store it in a variable:
kubectl get service nginx
ip=$(kubectl get svc nginx --template={{.spec.clusterIP}}- Check the nginx welcome page is there via a browser or downloading it with curl:
curl "http://$ip:8080"For further reading, see Kubernetes Documentation: Introduction to Kubernetes Architecture ›
Summary
Kubernetes is an orchestration tool for managing distributed services or containerized applications across a distributed cluster of nodes. It was designed for natively supporting (auto-)scaling, high availability, security and portability. Kubernetes itself follows a client-server architecture, with a master node composed of etcd cluster, kube-apiserver, kube-controller-manager, cloud-controller-manager, scheduler. Client (worker) nodes are composed of kube-proxy and kubelet components. Core concepts in Kubernetes include pods (a group of containers deployed together), services (a group of logical pods with a stable IP address) and deployments (a definition of the desired state for a pod or replica set, acted upon by a controller if the current state differs from the desired state), among others.
Top Kubernetes Architecture Tutorials from the Community
Understanding Kubernetes Architecture
Tutorial by: Edureka
Length: Medium
Can help you learn: Kubernetes Architecture
Tutorial steps:
- Kubernetes: An Overview
- Features Of Kubernetes
- Kubernetes Architecture
- Kubernetes Components
- Use Case
Kubernetes Tutorial – an Introduction to the Basics
Tutorial by: KeyCDN
Length: Long
Can help you learn: Set up Kubernetes on a single node on AWS, be able to run stateless and stateful applications, manage the Kubernetes cluster.
Tutorial Steps:
- The Need for Containerization, the nenefits of Kubernetes.
- Replication Controllers and Sets.
- Creating a Cluster.
- Configuring Kubectl
- The Kubernetes Dashboard
- Creating a Service
Kubernetes Training
Tutorial by: Cloud Native Computing Foundation
Length: Long
Can help you learn: Kubernetes basics, its architecture, and the problems it helps solves, model of Kubernetes for handling deployments and containerization, Kubernetes concepts like namespaces, replica sets, and deployments.
Tutorial steps:
- Introduction to Kubernetes, its fundamentals, architecture.
- What are deployments, pods, namespaces, replica sets.
- ConfigMaps, security, and administrative tasks to handle Kubernetes cluster.
Kubernetes Fundamentals
Tutorial by: The Linux Foundation
Length: Medium
Can help you learn: Introduction to Kubernetes, its architecture and concepts, how to do deployments in Kubernetes, monitoring and troubleshooting tasks.
Tutorial steps:
- Fundamentals to setup and configure a Kubernetes cluster.
- Replication controllers, deployments and volume mounting.
- What are services, namespaces, pods, and containers.
- Logging, monitoring, scheduling, federation and security.
Top Kubernetes Architecture Videos
This video helps understand the functionality of various Kubernetes components like etcd, kube-apiserver, scheduler, controllers, and how they interact with each other. It also gives information about Kubernetes master and nodes and various concepts like labels, namespaces, Replica sets, deployments, pods, and services. It also provides hands on guidance to launch pods in Kubernetes.
This video explains the role of containers in standardization of application development. It explains how containers and Kubernetes make it easy to deploy and ship an application that auto scales and auto heals.
